閱讀 Google 搜尋引擎最佳化官方指南,能幫助我們全面性地了解 SEO 發展方向與優化重點,為公司制定最佳的優化策略!文末附上簡要摘要,Happy learning!


















(延伸閱讀:主網域、子網域、網域寄放和附加網域是什麼?對SEO有何影響?)












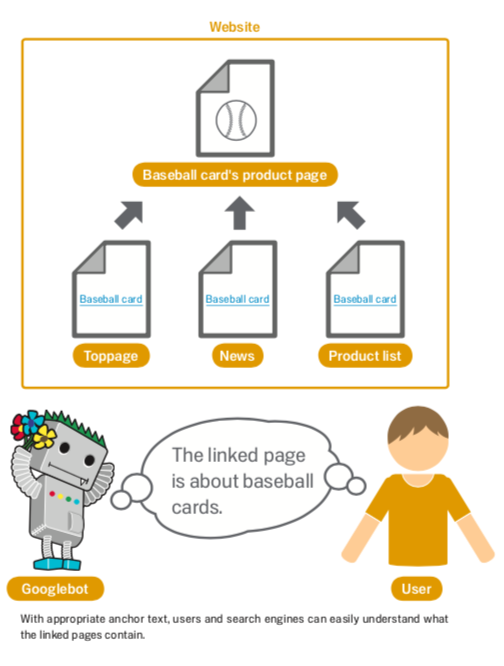



























Google SEO Starter Guide 重點摘要
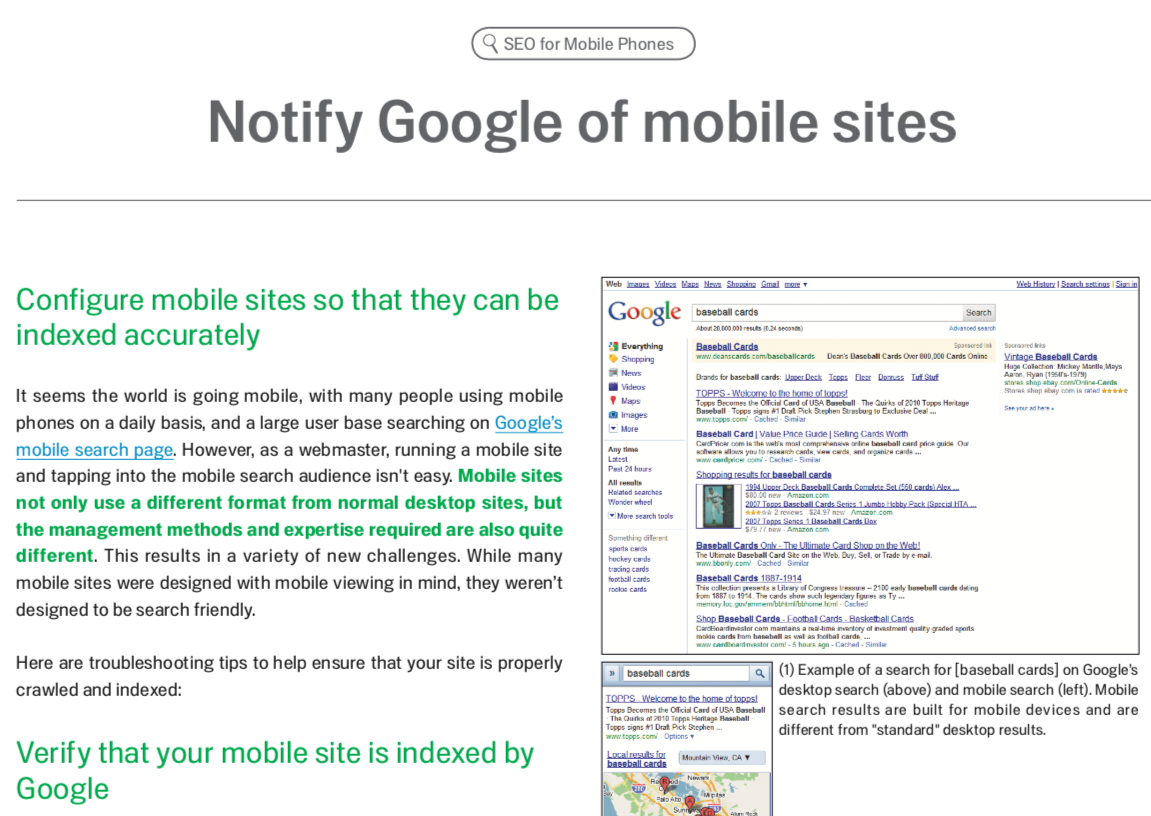
- 當 Google 判斷網頁無法讓手機讀取時,就不會顯示在手機的索引內 (網頁仍可查找到)
- 檢查是否有使用 DTD(Document Type Declaration, 文件類型宣告)
- 且類型是相容的 XHTML Mobile 或 Compact HTML DTD(Document Type Declaration, 文件類型宣告)
- CAPTCHA(Completely Automated Public Turing test to tell Computers and Humans Apart 全自動區分電腦和人類的公開圖靈測試),俗稱「驗證碼」,用來區分用戶是電腦或人的公共全自動程式
- 手機跟桌機看到的內容需相同,若不同會被視為 cloaking 並被懲罰,搜爬蜘蛛分別對應>> 桌機使用者=Googlebot;手機使用者=Googlebot-Mobile
- 若部落格有留言區,可以使用 nofollow 限制垃圾留言,如:<a href=”https://www.pwc.tw” rel=”nofollow”>Comment spammer</a>
- 可建立 XML Sitemap、HTML Sitemap、圖片 Sitemap 檔案、行動網頁 Sitemap
- 確認任何 User-agent,包括 “Googlebot-Mobile” 能進到網頁
- 因為 Google 可能不會通知 User- agent 的變更消息,所以不要限制 User- agent 一定要完全符合 “Googlebot-Mobile”,而是確保字串包含 “Googlebot-Mobile” 即可
- 亦可使用 DNS Lookups 去驗證 Googlebot
- 將照片補上 alt 屬性,當使用者未能讀取照片時能顯示文字敘述
如:<img src=”img_5terre_wide.jpg” alt=”Cinque Terre” width=”1000″ height=”300″> - 限制小蜘蛛!
- 使用 robotx.txt 告訴搜爬蜘蛛哪些網頁或檔案可以/不可爬,但它不是讓特定網頁
- 無法出現在 Google 搜尋結果中的機制(不會顯示標題、摘要,但仍會顯示 URL)
- 在 robots meta tag 中使用 NOINDEX,禁止自己的網頁出現在搜尋結果中
- 使用 htaccess,讓目錄 (directory) 需要密碼登入 > 高強度!
- 到 Google Search Console 去移除已被搜爬蜘蛛蒐集的資訊 (URL remover tool)
- 若要針對單一網址不被搜爬,使用 nofollow,如:meta name=”robots” content=”nofollow”


